Simulating systematic bias in attributed social networks and its effects on rankings of minority nodes
Abstract
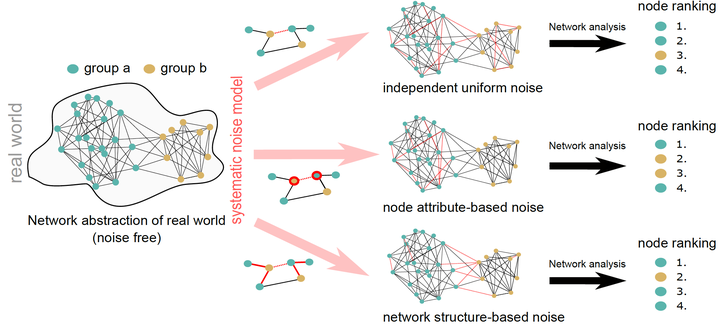
Network analysis provides powerful tools to learn about a variety of social systems. However, most analyses implicitly assume that the considered relational data is error-free, and reliable and accurately reflects the system to be analysed. Especially if the network consists of multiple groups (e.g., genders, races), this assumption conflicts with a range of systematic biases, measurement errors and other inaccuracies that are well documented in the literature. To investigate the effects of such errors we introduce a framework for simulating systematic bias in attributed networks. Our framework enables us to model erroneous edge observations that are driven by external node attributes or errors arising from the (hidden) network structure itself. We exemplify how systematic inaccuracies distort conclusions drawn from network analyses on the task of minority representations in degree-based rankings. By analysing synthetic and real networks with varying homophily levels and group sizes, we find that the effect of introducing systematic edge errors depends on both the type of edge error and the level of homophily in the system. In heterophilic networks, minority representations in rankings are very sensitive to the type of systematic edge error. In contrast, in homophilic networks we find that minorities are at a disadvantage regardless of the type of error present. We thus conclude that the implications of systematic bias in edge data depend on an interplay between network topology and type of systematic error. This emphasises the need for an error model framework as developed here, which provides a first step towards studying the effects of systematic edge-uncertainty for various network analysis tasks.
Leonie Neuhäuser
PhD Candidate in Computer Science
My research interests include Network Science, Complex Systems and Computational Social Sciences.